

Nächste Seite: Über dieses Dokument ...
Zum statistischen Vorhersagefehler von statistischen Modellen
Jürgen Grieser
17.02.98
Als statistisches Modell wird hier ein Modell verstanden, das eine beste
Anpassung zwischen 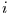 Einflußzeitreihen
Einflußzeitreihen 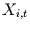 und einer Zielzeitreihe
und einer Zielzeitreihe
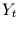 macht. Dieses Modell kann dann dazu verwendet werden, um die
Zielzeitreihe aufgrund vorhergehender oder weiterer Werte der
Einflußzeitreihe zu rekonstruieren bzw. vorherzusagen. Je nachdem wie gut die
Anpassung ist, wird man einen mehr oder weniger hohen statistischen Fehler
machen. Diesen gilt es abzuschätzen. Der statistische Fehler muß dabei klar
vom systematischen Fehler der Modellanpaßung unterschieden werden. Letzterer kann als
vernachlässigbar angesehen werden, wenn das Residuum aus aufgrund der
Anpassung erklärtem Anteil an der Zielzeitreihe
macht. Dieses Modell kann dann dazu verwendet werden, um die
Zielzeitreihe aufgrund vorhergehender oder weiterer Werte der
Einflußzeitreihe zu rekonstruieren bzw. vorherzusagen. Je nachdem wie gut die
Anpassung ist, wird man einen mehr oder weniger hohen statistischen Fehler
machen. Diesen gilt es abzuschätzen. Der statistische Fehler muß dabei klar
vom systematischen Fehler der Modellanpaßung unterschieden werden. Letzterer kann als
vernachlässigbar angesehen werden, wenn das Residuum aus aufgrund der
Anpassung erklärtem Anteil an der Zielzeitreihe
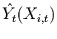 und
der Zielzeitreihe selbst als Rauschen aufgefaßt werden kann. Dann trägt nur
noch dieses statistische Rauschen zum Fehler der Vorhersage oder
Rekonstruktion bei. Hier soll nun angegeben werden, wie unter dieser
Vorraussetzung der statistische Fehler der Vorhersage bzw. Rekonstruktion
von der erklärten Varianz der Anpassung und der Standardabweichung der
Rekonstruktion abhängt. Dazu wird zunächst die Varianz der Zielzeitreihe
und
der Zielzeitreihe selbst als Rauschen aufgefaßt werden kann. Dann trägt nur
noch dieses statistische Rauschen zum Fehler der Vorhersage oder
Rekonstruktion bei. Hier soll nun angegeben werden, wie unter dieser
Vorraussetzung der statistische Fehler der Vorhersage bzw. Rekonstruktion
von der erklärten Varianz der Anpassung und der Standardabweichung der
Rekonstruktion abhängt. Dazu wird zunächst die Varianz der Zielzeitreihe
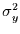 in zwei Anteile aufgespalten:
in zwei Anteile aufgespalten:
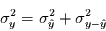 |
(1) |
wobei
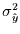 der Anteil der Varianz ist, der durch die
Einflußzeitreihen erklärt wird, während
der Anteil der Varianz ist, der durch die
Einflußzeitreihen erklärt wird, während
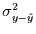 der Anteil
der Varianz von ist, der nicht durch die erklärt ist. Teilt
man Gleichung (1) durch
so erhält man
folgenden Ausdruck
der Anteil
der Varianz von ist, der nicht durch die erklärt ist. Teilt
man Gleichung (1) durch
so erhält man
folgenden Ausdruck
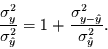 |
(2) |
Nun ist der Ausdruck auf der linken Seite von Gleichung (2) gleich
dem Reziproken des Bestimmtheitsmaßes 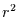 (oft auch erklärte Varianz
genannt, obwohl es keine Varianz ist, sondern ein Varianzanteil). Setzt man
in Gleichung (2) ein, stellt nach dem rechten Term auf der
rechten Seite um und zieht die Wurzel, so erhält man
(oft auch erklärte Varianz
genannt, obwohl es keine Varianz ist, sondern ein Varianzanteil). Setzt man
in Gleichung (2) ein, stellt nach dem rechten Term auf der
rechten Seite um und zieht die Wurzel, so erhält man
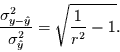 |
(3) |
Gleichung (3) gibt demnach die Abhängigkeit des Verhältnisses der Standardabweichung des
nicht erklärten Anteils zu der des erklärten Anteils als Funktion des
Bestimmtheitsmaßes an. Sie ist in Abbildung 1 dargestellt. Damit
ist man in der Lage aus der Standardabweichung der Vorhersage oder
Rekonstruktion auf die Standardabweichung des zugehörigen statistischen
Fehlers zu schließen. Aus der Kenntnis von
können
dann Vertrauensgrenzen für die Vorhersage- bzw. Rekonstruktionswerte angegeben
werden. Unter der Bedingung, daß der statistische Fehler normalverteilt ist,
folgt